How to back up your site cheaply with Amazon S3 and s3sync
The two main parts of WordPress and other popular CMS-powered websites are the database and the files. Your web host might keep regular backups of all elements of your site, but the unfortunate thing is that sometimes when your server is down, that is the most difficult time to access your host’s backups (as I discovered with a shared host). So it’s good to consider your own backup solutions.
If you have a MySQL database, a simple mysqldump command can save the database as a file and you can potentially e-mail it to yourself if it’s small enough. With or without the dumped database file, you then have to back up the rest of the files. Dropbox is a creative solution, but an easier and more direct solution is to use Amazon’s Simple Storage Service, otherwise known as Amazon S3. S3 is a service that’s part of the much hyped cloud computing, a land of seemingly infinite data and virtualized resources. Amazon S3 is cheap, well-documented, robust, easy-to-use, and there are many good scripts to interface with S3. It is more than just a good backup option, but for this post I’ll only talk about it within the context of backups.
Amazon S3’s costs are pay-per-use / pay-as-you-go and are split into a few categories:
- Storage: starting at $0.15 per gigabyte
- Data transfer in: Free until November 1, 2010; usually starting at $0.10 per GB
- Data transfer out: starting at $0.15 per GB
- Put and similar requests: 0.01 per 1,000 requests (if you have lots of files this will be the initial input)
Account management in Amazon breaks this down really well into minute details. My blog is relatively small, as I’ve only accumulated about 100mb of files in 4 years and the database is less than 2mb compressed. My monthly cost for daily and weekly backups is less than 20 cents.
Here are a few ways to get the most out of using Amazon S3 for backups:
- Back up only what you need to. Most CMSs let you place all your modifications in one or only a few places. In the case of WordPress, if your entire site is contained in plugins, themes, and uploads, you might only need to back up the wp-content/ folder, since you could restore the rest of the site from a downloaded instance of WordPress.
- Look into some of S3’s extra features, such as versioning and access control by IP as discussed in its FAQ
- Although Amazon S3 claims to be designed to provide “99.999999999% durability and 99.99% availability of objects over a given year”, it could still fail at the same time that your server fails. To mitigate this already-small risk, you could back up to multiple S3 regions, or look at a supplementary backup service such as Rackspace Cloud Files
- To actually access the backed up files, you can use the web-based AWS Management Console to view and download files, make them publicly accessible if needed, create “buckets” (top-level folders, which you can store in different physical locations). One of the more useful tools is a Firefox plugin called S3Fox Organizer, which lets you do much of the same stuff in a familiar explorer-like, two-panel interface (where you can drag-and-drop between your local file system on the left and the remote files on the right):
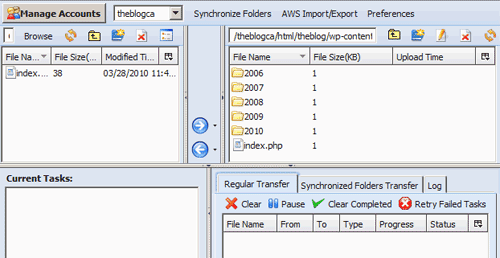
If you need a step-by-step process to using Amazon S3 starting with the sign-up process, check out this post. Below are my notes on how to use the free s3sync and s3fs tools for the actual backup process. Both assume that you’ve already created a bucket via the AWS Management Console or S3Fox Organizer, although you can also use both tools to create buckets.
s3sync
s3sync is a script written in Ruby. Ruby is usually installed on Linux servers and is easy to install if needed.
There are 3 main steps to start using s3sync.
Download and extract the script
You can currently download the latest version of s3sync at:
http://s3.amazonaws.com/ServEdge_pub/s3sync/s3sync.tar.gz
Then, you can extract the file through your control panel or with a simple tar command:
tar -zxf s3sync.tar.gz
Create a configuration file
You’ll need to make a copy of the included s3config.yml.example file. It is very simple and has only two required lines:
aws_access_key_id: your_access_key_id
aws_secret_access_key: your_secret_access_key
You can get both the access key ID and the secret access key on your account when you sign in to Amazon Web Services. Go to Account > Security Credentials.
As for where to place the configuration file, take a look at s3config.rb. Line 15 shows:
confpath = ["#{ENV['S3CONF']}", "#{ENV['HOME']}/.s3conf", "/etc/s3conf"]
So you can either place the s3config.yml file in a self-defined environmental variable (if you have command line access); or in your user’s home directory (usually /home/yourusername/.s3conf/s3config.yml) or in etc/s3conf/s3config.yml. If all else fails, you can just edit s3config.rb and hardcode a path!
Run the script
Before you set up your full backup, you can test that your credentials and connection are working properly by listing the buckets on your account. The command is simply:
./s3cmd.rb listbuckets
Note that s3cmd.rb needs to have executable permissions. If you don’t have command line / shell access to your server, you likely have access to a control panel where you can set up a cron job to execute s3cmd.rb. Just make sure that the cron job either refers to the full path where s3cmd.rb sits, or that it first changes directory (cd) into the folder to which you’ve extracted s3sync.
If all is well, you can then run the full backup script and then set up a cron job to back up your files daily and weekly (or at whatever frequency you’d like).
/path/to/s3sync/s3sync.rb -r /path/to/your/site theblog:daily
The command would back up your site to an existing bucket “theblog” under a sub-folder “daily”.
s3sync can also do many other Amazon S3 management tasks. Check the well-detailed README file for more information.
s3fs
s3fs is a simple solution for VPS and dedicated servers that enables you to mount an Amazon S3 bucket via a local FUSE file system. You can thus access your backup and sync it more or less locally.
(A quick note to VPS users — first, make sure that FUSE has been installed on the hardware node of the VPS setup! Your hosting company will have to do this for you. Otherwise, you might struggle with errors that seem to be file permission related (“fuse: failed to open /dev/fuse: Permission denied”) but that are in fact not simply chmod, chown, or user group fixable!)
If needed, install the fuse, fuse-devel, and curl-devel packages on your server. If you’re on Red Hat, Fedora, or CentOS, you can make use of yum:
yum install fuse
yum install fuse-devel
yum install curl-devel
Then, download and extract the latest s3fs source files from the s3fs website. You’ll have to compile the source, but that’s usually a simple “make -f Makefile” command. Then, move the s3fs binary into /usr/bin and you’re ready to mount the Amazon S3 bucket!
/usr/bin/s3fs name_of_bucket -o accessKeyId=aaaa -o secretAccessKey=aaaa /mount_path
As noted in the above s3sync notes, you can get both the access key ID and the secret access key on your account when you sign in to Amazon Web Services. Go to Account > Security Credentials.
You can use the friendly rsync command to produce daily, weekly, or other frequency of backups:
rsync -av --delete /path/to/your/site/ /mount_path/daily




 keung.biz. Hire my web consulting services at
keung.biz. Hire my web consulting services at 

